문자 인코딩(Character Encoding)
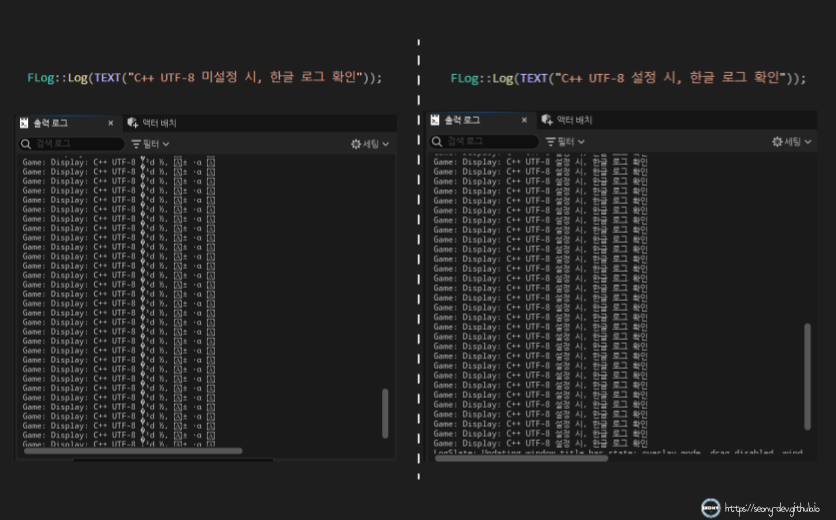
▲ UTF-8 인코딩 설정 전·후 한글 로그 출력 비교
🖥️ 문자 인코딩이란?
문자 인코딩(Character Encoding)은 문자를 컴퓨터에서 표현하고 저장하는 방식.
인코딩 방식에 따라 문자 집합이 다르고, 문자 데이터를 저장하는 방법도 달라짐.
대표적인 문자 인코딩 방식으로 ASCII, 유니코드(Unicode), UTF-8, UTF-16 등이 있음.
🖥️ ASCII (American Standard Code for Information Interchange)
초기 문자 인코딩 방식으로, 영어(라틴 문자)만 표현 가능
| 비트 수 | 표현 가능한 문자 | 예시 |
|---|---|---|
| 7비트 (128개 문자) | 영문 대/소문자, 숫자, 특수기호 | A=65 (0x41), a=97 (0x61), 0=48 (0x30) |
| 8비트 확장 ASCII | 일부 유럽어 문자 추가 | é, ñ, ö 등 |
📌 문제점: ASCII는 한글, 중국어, 일본어 같은 다국어 지원 불가 → 유니코드 필요!
🖥️ 유니코드(Unicode)
전 세계의 모든 문자를 하나의 표준으로 통합한 문자 인코딩 방식
- 코드 포인트: 유니코드는 각 문자에 고유한 코드 포인트(ex:
U+0041 = 'A')를 부여함. - 다국어 지원: 한글, 중국어, 일본어, 특수 기호 등 전 세계의 문자 표현 가능.
- 대표적인 유니코드 인코딩 방식: UTF-8, UTF-16, UTF-32
🖥️ UTF-8 vs UTF-16 비교
| 인코딩 방식 | 특징 | 장점 | 단점 |
|---|---|---|---|
| UTF-8 | 가변 길이(1~4바이트) | ASCII와 호환됨, 공간 절약 | 동아시아 문자 표현 시 공간 비효율적 |
| UTF-16 | 고정 길이(2 또는 4바이트) | 대부분의 언어에서 일정한 크기로 표현 가능 | ASCII와 호환되지 않음, 저장 공간 증가 |
📌 UTF-8은 웹 개발과 네트워크 통신에서 주로 사용되고, UTF-16은 Windows 및 일부 애플리케이션에서 사용됨.
🖥️ UTF-8과 UTF-16의 인코딩 방식
🔹 UTF-8 인코딩 방식
- 가변 길이 인코딩 (1~4바이트)
- 영어(ASCII 문자)는 1바이트로 표현됨
- 한글, 한자 같은 문자는 2~3바이트 이상 필요
📌 UTF-8 예제 (가 → UTF-8 변환)
유니코드 값: U+AC00
UTF-8 인코딩: 0xEA 0xB0 0x80 (3바이트)
🔹 UTF-16 인코딩 방식
- 고정 길이 인코딩 (2바이트 또는 4바이트)
- 기본적으로 2바이트 사용, 일부 확장 문자는 4바이트 사용
📌 UTF-16 예제 (가 → UTF-16 변환)
유니코드 값: U+AC00
UTF-16 인코딩: 0xAC00 (2바이트)
🖥️ 유니코드 활용 사례
| 사용 환경 | UTF-8 | UTF-16 | |———-|——-|——–| | 웹 및 네트워크 | ⭕ (HTML, JSON, XML) | ❌ | | 운영 체제 | ⭕ (Linux, macOS) | ⭕ (Windows) | | 게임 엔진 | ⭕ (Unreal Engine) | ⭕ (Unity) | | 문서 저장 형식 | ⭕ (BOM 없이 사용 가능) | ❌ (BOM 필요) |
- ※ BOM (Byte Order Mark)
- UTF-8에서는 선택 사항이지만, UTF-16/UTF-32에서는 바이트 순서를 식별하는 역할을 하며 일부 프로그램에서 호환성 문제를 일으킬 수 있음.
언리얼 엔진에서 UTF-8 사용 예제
FString utf8String = "새해 복 많이 받으세요";
FTCHARToUTF8 utf8Converter(*utf8String);
UE_LOG(LogTemp, Log, TEXT("UTF-8 인코딩: %s"), utf8Converter.Get());
UTF-16 변환 예제 (C++)
#include <cstdio>
#include <codecvt>
#include <locale>
using namespace std;
int main()
{
wstring_convert<codecvt_utf8_utf16<wchar_t>> converter;
wstring utf16Str = L"새해 복 많이 받으세요";
string utf8Str = converter.to_bytes(utf16Str);
printf("UTF-8: %s\n", utf8Str.c_str());
return 0;
}
출력 결과:
UTF-8: 새해 복 많이 받으세요
🖥️ 문자 인코딩 사용 시 주의할 점
ASCII는 영어만 지원하며, 다국어 지원 불가UTF-8과UTF-16은 서로 호환되지 않으므로 변환 필요UTF-16은BOM(Byte Order Mark)문제를 고려해야 함- 파일 및 데이터 전송 시 인코딩 명시가 중요
출처 :
* https://en.wikipedia.org/wiki/Character_encoding
* https://www.unicode.org/standard/WhatIsUnicode.html
* https://developer.mozilla.org/en-US/docs/Web/Guide/Localizations_and_Character_encodings
* https://www.asciitable.com/